AI Legal Battles Escalate: A Visual Map of Over 100 Lawsuits Shaping the Industry
A comprehensive visual analysis details the growing landscape of lawsuits against major AI developers, highlighting copyright infringement claims and the potential impact on the future of AI development.
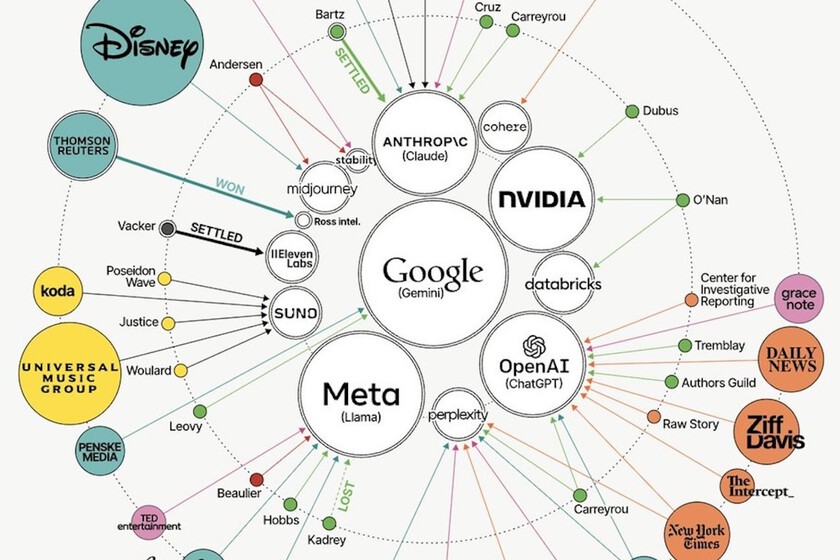
The artificial intelligence landscape is increasingly defined not just by technological advancements, but by a burgeoning wave of legal challenges. A detailed analysis, visualized by David McCandless for Information is Beautiful, maps over 100 lawsuits filed against prominent AI developers in the United States. These legal battles, centered on copyright infringement and the unauthorized use of data for training AI models, are poised to significantly shape the future trajectory of AI development and business models.
The core of these disputes revolves around how AI companies have acquired the vast datasets necessary to train sophisticated models like ChatGPT, Gemini, and Meta AI. The prevailing strategy has been characterized as “it’s better to ask for forgiveness than permission,” leading AI firms to source data from books, journalistic articles, song lyrics, illustrations, and source code without explicit permission or compensation. This approach has resulted in a multitude of claims from creators and rights holders who allege their works have been used to build systems that now compete with them.
Por que importa
Key Facts
| Detail | Information |
|---|---|
| Number of Lawsuits | Over 100 active lawsuits in US courts as of June 2026. |
| Primary Allegation | Copyright infringement and unauthorized use of data for AI model training. |
| Central Defendants | Major AI developers including OpenAI, Google, Meta, Anthropic, NVIDIA, and Perplexity. |
| Plaintiffs | A diverse group including writers, media outlets, artists, and platforms. |
| Regulatory Landscape | US Copyright Office report indicates no universal fair use answer; EU regulations are more restrictive. |
The visual map places major AI companies at its center, with various plaintiffs radiating outwards. Each category of plaintiff is color-coded, and the size of the circle represents the scale of the company. A crucial disclaimer notes that when a plaintiff has multiple open lawsuits, only the primary defendant is depicted, suggesting the true number of legal conflicts may be even higher.
Significant cases highlighted in the analysis include:
- Bartz vs. Anthropic: Anthropic reportedly settled for $1.5 billion after allegations of downloading hundreds of thousands of books from unofficial repositories. While the court validated the training as fair use, the method of data acquisition was questioned.
- Kadrey vs. Meta: Meta’s training practices are under scrutiny, with a victory in the training phase but ongoing litigation regarding the distribution of pirated content.
- New York Times vs. OpenAI: The New York Times alleges that ChatGPT can reproduce its articles almost verbatim, circumventing the original source. This case is currently ongoing.
- Disney vs. Midjourney: Major entertainment studios are actively engaged in legal action against AI image generation tools.
- Concord, BMG, and Universal vs. Anthropic: Major record labels are suing over the alleged reproduction of copyrighted song lyrics.
The US Copyright Office released a 108-page report in May 2025, concluding that there is no blanket fair use determination for AI training. Each case must be assessed individually, acknowledging that neither companies nor their uses are uniform.
The financial implications are substantial. Anthropic’s settlement, while large, was absorbed by its significant valuation, indicating that for some companies, the “ask for forgiveness” model has, thus far, been economically viable. However, the ongoing barrage of lawsuits raises questions about the sustainability of this approach and the potential for clearer regulations governing data usage in AI development.
The European Union presents a contrasting regulatory environment. The AI Act mandates that companies disclose the data used for training and allows creators to reserve their rights. This stricter framework contrasts with the more permissive, case-by-case approach seen in the United States, suggesting divergent paths for AI development globally.
The outcome of these legal battles will have profound implications, potentially necessitating retroactive licensing fees, requiring a significant overhaul of data collection practices, and fundamentally altering how AI models are developed and deployed. For readers of ReviewArticle, understanding these legal challenges is crucial for staying informed about the evolving regulatory and ethical landscape of artificial intelligence.
Source: Quién está demandando a quién en la IA: el mapa de los 100 juicios que lo explica todo, Xataka, https://www.xataka.com/servicios/quien-esta-demandando-a-quien-ia-mapa-100-juicios-que-explica-todo
Source
Xataka IA Publicacion original: 2026-06-27T08:00:13+00:00
Related articles

Experts Highlight Lifestyle Factors Over Coffee Consumption for Functional Stamina
While moderate coffee intake is generally considered safe and potentially beneficial, experts warn that reliance on multiple cups to function points to…
Read article
Valencian Family Pivots from Coca-Cola to Photonics with State Chip Funding
A historic Valencian family, with deep ties to Coca-Cola bottling, is making a significant technological leap by investing in Attypics Photonics, a…
Read article
EU AI Act compliance documents to ask vendors for before renewal season
A practical, evidence-led checklist for asking AI vendors for compliance and governance documentation before renewals—while separating formal legal evidence from broader due-diligence…
Read article
Lidl’s Budget Smart Tracker Offers Cross-Platform Compatibility for Under $10
A new smart tracker from Lidl, priced at just €8.99, boasts native compatibility with both Apple's "Find My" network and Google's "Find…
Read articleWiki relacionada

Understanding Large Language Models (LLMs)
An introduction to Large Language Models (LLMs), their architecture, capabilities, limitations, and real-world applications in AI.
Read article
Understanding LLM Context Windows
An in-depth look at Large Language Model context windows, their importance, limitations, and how they impact AI applications.
Read article
Comprendiendo los Modelos Llama 3: Una Visión Integral
Explore la familia de modelos Llama 3, detallando su arquitectura, capacidades, limitaciones y aplicaciones prácticas en el desarrollo de IA.
Read article
Comprensión de los Modelos de Lenguaje Grandes (LLM)
Una mirada en profundidad a los Modelos de Lenguaje Grandes (LLM), su arquitectura, capacidades, limitaciones e impacto en el desarrollo de la…
Read article