Arize AI Details Production-Ready LLM-as-a-Judge Evaluation Framework
Arize AI has released a detailed guide on building LLM-as-a-Judge evaluators for production environments, focusing on robust criteria, fixed labels, human agreement, and cost efficiency. The framework emphasizes practical application for AI developers and MLOps teams.
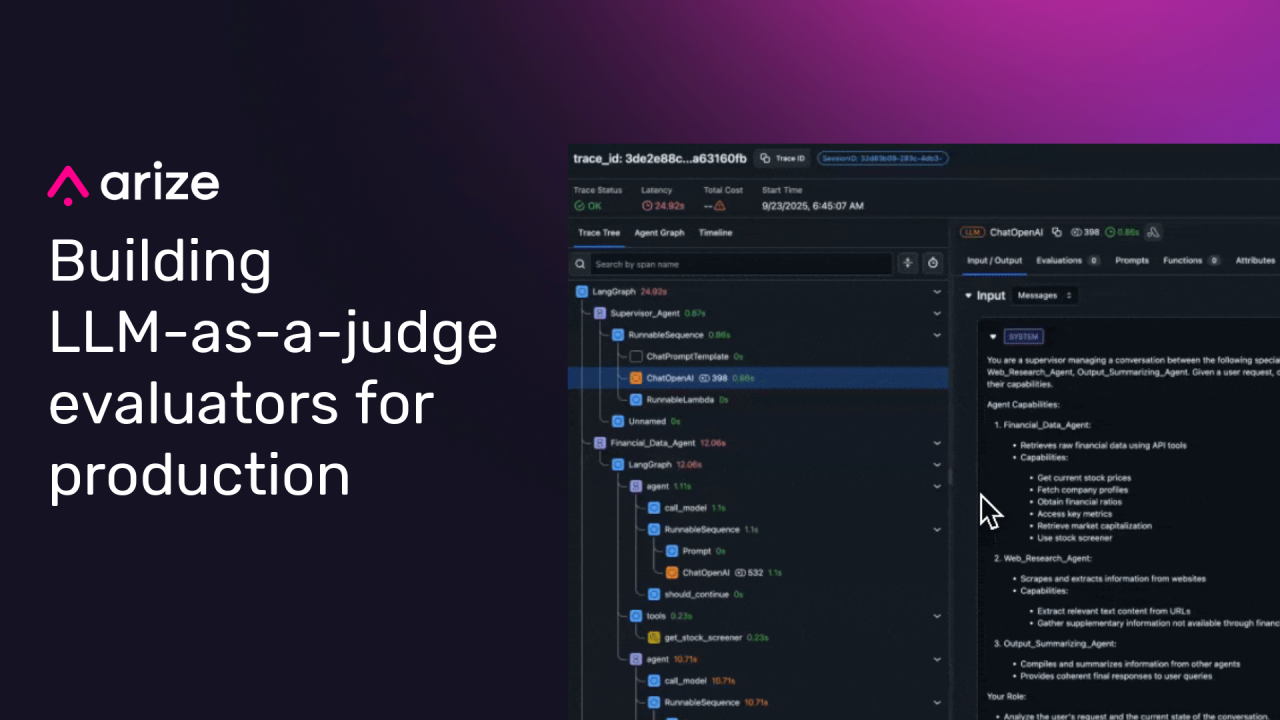
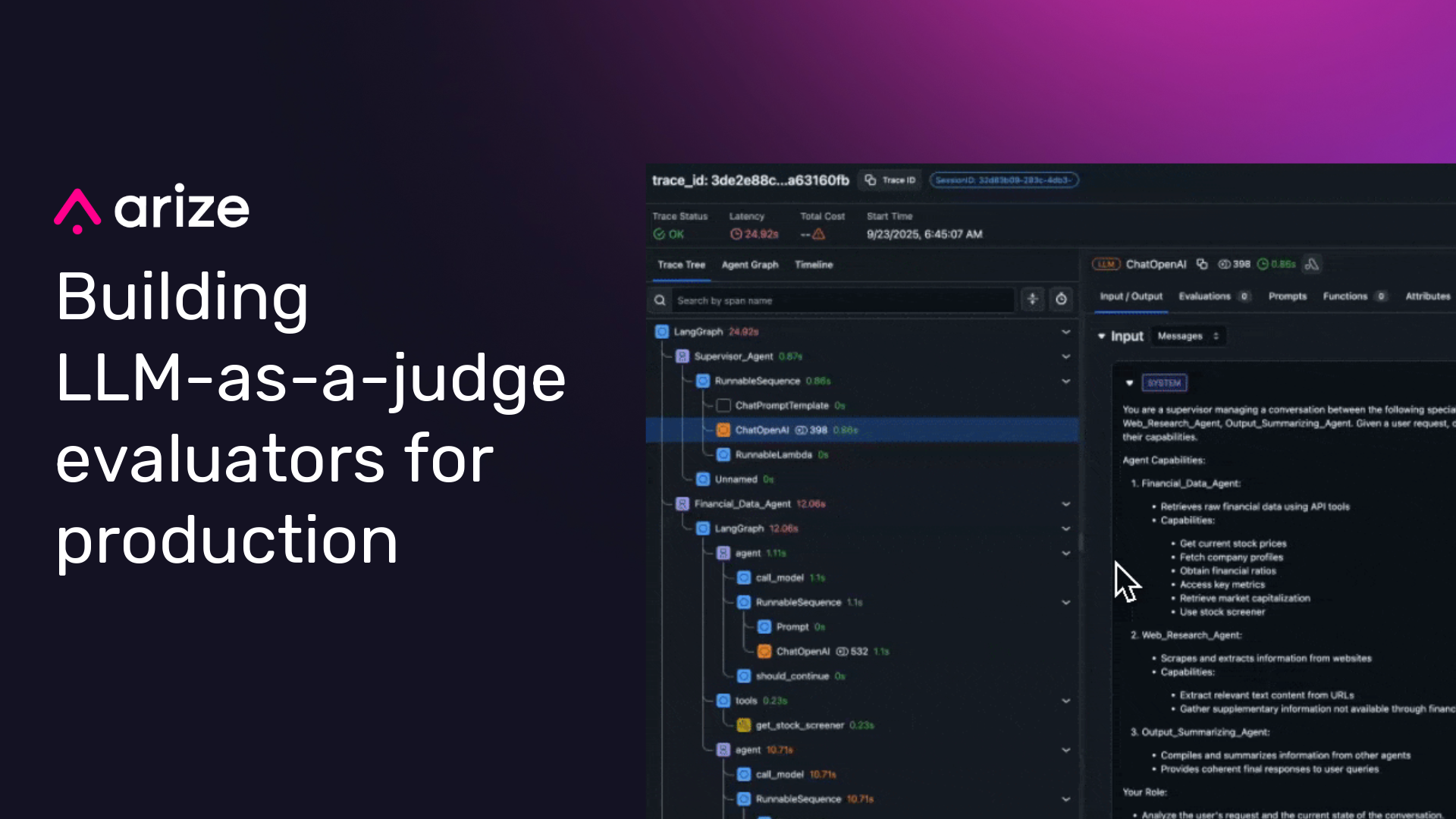
Arize AI has published a comprehensive guide outlining how to construct and implement LLM-as-a-Judge evaluators designed for reliable performance in production environments. The guidance addresses common pitfalls in LLM evaluation, advocating for a structured approach that prioritizes clear criteria, fixed labeling systems, human agreement checks, and efficient resource utilization. This framework is particularly relevant for developers and MLOps teams building and deploying sophisticated LLM-powered applications and agents where scalable, consistent evaluation is critical.
The core premise of the Arize AI guidance is that while LLM-as-a-Judge offers significant scalability over manual review, its effectiveness hinges on the precision and context of the evaluation setup. A key distinction made is between evaluations that can be handled by deterministic code and those requiring semantic interpretation by an LLM judge. Simple checks like JSON validity, tool schema adherence, or latency thresholds are best managed with code, which is faster, cheaper, and more predictable. LLM judges, however, excel when evaluating nuanced aspects like answer correctness, tone, user frustration, or overall task completion, which are difficult to codify with rules.
Key facts:
- Primary Use Case: Semantic evaluation of LLM outputs, traces, and sessions where meaning is critical.
- Evaluation Design: Emphasizes fixed labels, explicit criteria, human agreement, and trace context.
- Cost & Latency Control: Recommends using code for deterministic checks and LLM judges only for semantic interpretation.
- Observability Link: Integrates evaluation results with observability platforms to drive iterative model improvement.
Designing Robust Evaluation Criteria
A central tenet of Arize AI’s approach is the meticulous definition of evaluation criteria. Vague prompts like “rate helpfulness from 1 to 5” or “determine whether the answer is good” lead to meaningless scores because they lack explicit definitions of what constitutes “good” or “helpful.” Instead, the guide proposes a five-part structure for strong evaluation criteria: an evaluation target, allowed labels, decision rules, examples, and edge cases.
For instance, evaluating “task completion” for a customer support agent might involve labels such as `resolved`, `partially_resolved`, `unresolved`, and `insufficient_evidence`. Crucially, specific decision rules would govern when each label applies. For example, an agent’s response is not `resolved` if the user had to repeat the request or if required tool evidence is missing. Similarly, `unresolved` should not be applied simply because an agent escalated a case, as escalation quality might be a separate evaluation concern. This granular approach ensures that each evaluator measures a single, well-defined dimension, preventing ambiguous scores that blend multiple factors.
Balancing LLM Judges with Code-Based Checks
The guide clarifies that LLM judges and code-based evaluators are complementary, not competing, tools. Many production systems will employ both. For example, a customer support agent might use code to verify JSON output, tool-call schemas, and latency, while simultaneously using an LLM judge to assess answer correctness, tone, and user frustration. A Retrieval-Augmented Generation (RAG) system might use code to check citation format, then deploy an LLM judge to determine if the cited source genuinely supports the generated answer.
The practical rule offered is straightforward: if an answer can be checked without semantic interpretation, use code. If it depends on meaning, use an LLM judge. This distinction helps optimize resources, as deterministic code checks are generally more efficient and cheaper to run than LLM inference. Attaching judge outputs to trace context is also recommended to enable inspection and debugging when automated actions are driven by evaluation results.
The Importance of Fixed Labels and Human Calibration
Arize AI advocates for fixed labels over open-ended scores where possible. Fixed labels, such as `resolved` or `unresolved`, provide discrete, unambiguous categories that are easier to calibrate and aggregate consistently. This structured output facilitates comparison over time and across different model versions.
Human agreement checks are presented as a vital step in calibrating LLM judges. By comparing an LLM judge’s assessments against human reviewers for a subset of examples, teams can identify discrepancies, refine prompt instructions, and ensure the judge aligns with human understanding. This calibration process helps build confidence in the automated evaluation system and ensures it measures what humans intend it to measure.
Evaluating Agent Trajectories and Cost Control
For complex AI agents, evaluating entire trajectories or sessions is often more informative than isolated outputs. LLM-as-a-Judge can assess whether an agent followed the correct sequence of actions, used tools appropriately, and ultimately achieved the user’s goal over multiple turns. This is particularly relevant for multi-step tasks where the overall flow and coherence are critical.
Cost and latency are significant considerations in production. The guide advises careful design to minimize unnecessary LLM calls. By offloading deterministic checks to code and limiting the LLM judge’s scope to semantic interpretation, teams can reduce inference costs and accelerate evaluation cycles. The integration with observability platforms like Arize:Observe allows teams to monitor evaluation performance, identify drift, and continuously improve their LLM applications by closing the loop between observation and evaluation.
Source: Arize AI Blog – How to build LLM-as-a-Judge evaluators that hold up in production
Source
Arize AI Blog Publicacion original: 2026-05-21T14:00:45+00:00
Related articles
X Money App Launches for US Subscribers — A Fintech Move With AI Ecosystem Implications
X (formerly Twitter) begins rolling out its X Money app to Premium and Premium+ subscribers in the United States, offering a Visa…
Read article
China’s Matchmaking App Raises Questions About AI’s Role in Solving Demographic Crisis
A government-backed dating app in China, described as a “kind of Tinder for young people,” has drawn attention amid the country’s falling…
Read article
China’s New AI Billionaires: DeepSeek Founder Tops $36 Billion as Low-Profile Tech Elite Rises
A new generation of Chinese tech billionaires, led by DeepSeek’s Liang Wenfeng and CXMT’s Zhu Yiming, is building AI and semiconductor fortunes…
Read article
How an Algorithm Engineered an Instant Influencer With 400,000 Followers in Three Days
At a live-streamed boxing event in Spain, a young woman with zero social-media posts gained hundreds of thousands of followers in hours.…
Read articleWiki relacionada

What Is RAG? A Practical Guide to Retrieval-Augmented Generation in 2025
Retrieval-Augmented Generation (RAG) grounds LLM outputs in external data, reducing hallucinations and enabling enterprise use cases. This guide covers how RAG works,…
Read article
Retrieval-Augmented Generation (RAG) – How It Works, Why It Matters, and Where It Falls Short
A practical guide to Retrieval-Augmented Generation (RAG): how it reduces LLM hallucinations, the components needed, real-world developer workflows, and key limitations to…
Read article
Mistral AI Models and API: A Developer Overview
Mistral AI offers a family of open-weight and proprietary models for developers, from Mistral 7B to Mistral Large. This guide covers model…
Read article
What Is Retrieval-Augmented Generation (RAG)? A Developer’s Guide
Retrieval-augmented generation (RAG) combines LLMs with external knowledge retrieval to reduce hallucinations, keep facts current, and enable enterprise-grade AI workflows. This guide…
Read article