Meta Reimagines Petabyte-Scale Data Ingestion for Enhanced Reliability
Meta's engineering team details a complex migration of its petabyte-scale MySQL data ingestion platform, prioritizing reliability and operational efficiency through staged rollouts and continuous validation.
Meta’s engineering team has successfully navigated the intricate process of migrating its data ingestion platform, a critical system responsible for transferring petabytes of daily MySQL social graph data. The initiative aimed to bolster reliability and streamline operational efficiency across the company’s vast data infrastructure.
The platform underpins essential functions including analytics, reporting, machine learning, and internal product development. In a significant architectural shift, Meta transitioned from fragmented, customer-managed pipelines to a centralized, self-managed warehouse service. This overhaul involved a meticulous approach to migration, employing staged transitions, automated validation processes, robust rollback mechanisms, and compatibility layers to ensure the seamless movement of thousands of ingestion pipelines without disrupting downstream operations.
Staged Migration Approach
The migration was executed in three distinct stages, a strategy designed to minimize risk and ensure data integrity at every step:
Shadow Phase: In this initial phase, the new system was run in parallel with the existing production environment. This allowed engineers to validate the new platform’s performance and accuracy against live production data without impacting live services.
Reverse Shadow Phase: Following successful validation, production ownership was carefully transferred to the new system. Crucially, the capability to roll back to the legacy pipeline remained active, providing a safety net in case of unforeseen issues.
Cleanup Phase: Once consistency and performance checks were thoroughly passed and the new system demonstrated sustained reliability, the legacy pipeline was retired.
Continuous Monitoring and Validation
A cornerstone of the migration’s success was the implementation of continuous monitoring and validation. Zihao Tao, a software engineer at Meta, and his colleagues emphasized the importance of this process: “We continuously monitored row count and checksum mismatches between the production jobs and the shadow jobs. When mismatches occurred, we quickly investigated the root cause and deployed fixes to the pre-production environment, then verified that the mismatch was resolved.”
This rigorous approach extended to resource management. Before fully committing to the new system, the team meticulously measured the compute and storage quotas required by the shadow jobs. This ensured that the production environment possessed sufficient resources to handle the load before the transition.
Change Data Capture Architecture
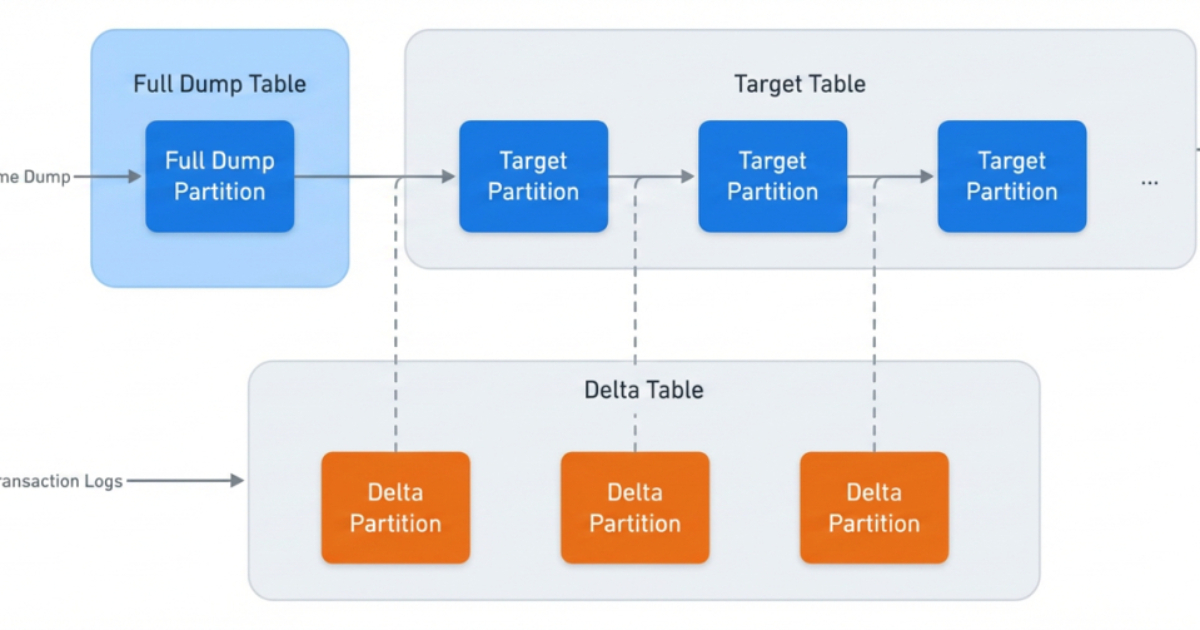
Both Meta’s legacy and the newly redesigned data ingestion systems leverage Change Data Capture (CDC) to incrementally ingest data into target tables. Each ingestion job maintains internal tables for full data dumps from source databases, a separate table for capturing incremental changes (delta), and a final target table for consumption by data customers. The central management service meticulously stores and manages all job entity information, including table names and schemas.
Addressing Migration Challenges
The scale of this migration presented significant challenges. Syed Moeen Kazmi noted, “Migrating data ingestion at Meta scale isn’t an upgrade. It’s open-heart surgery on core business. The challenge isn’t just moving data, it’s maintaining consistency and zero downtime.”
To mitigate the impact of CDC’s reliance on potentially resource-intensive full snapshots for initial loads and post-fix recovery, Meta focused on minimizing the creation of unnecessary shadow jobs until data quality issues were resolved. This strategy significantly reduced the frequency of large-scale full dumps, thereby improving migration efficiency. Furthermore, the team optimized infrastructure load by reusing snapshot partitions from the legacy system during the initial migration stages.
The successful completion of this migration underscores Meta’s commitment to maintaining a highly reliable and efficient data infrastructure capable of handling petabyte-scale operations. The meticulous planning, phased rollout, and continuous validation employed in this project offer valuable insights into managing complex data engineering challenges at hyperscale.
Datos clave
| Aspect | Detail |
|—————————-|——————————————–|
| Company | Meta |
| Data Volume | Petabytes daily |
| Database System | MySQL |
| Migration Goal | Improved reliability and operational efficiency |
| Key Techniques | Reverse shadowing, checksum monitoring, staged migrations |
This development is significant for ReviewArticle readers, particularly those interested in AI News and Data, as it highlights the sophisticated engineering required to manage the massive datasets that fuel modern AI and data-driven applications. The focus on reliability and zero downtime in such a critical infrastructure component demonstrates best practices applicable to large-scale data operations.
Fuente: infoq.com (https://www.infoq.com/news/2026/05/meta-cdc-migration/?utm_campaign=infoq_content&utm_source=infoq&utm_medium=feed&utm_term=global)
Datos clave
| Punto | Detalle |
|---|---|
| Fuente | infoq.com |
| Fecha | 2026-05-30T06:01:00+00:00 |
| Tema | How Meta Rebuilt Data Ingestion for Petabyte-Scale Reliability |
Source
infoq.com Publicacion original: 2026-05-30T06:01:00+00:00
Related articles

Satellite Imagery Reveals Significant Russian Military Buildup Near NATO Borders
New satellite data and intelligence analyses indicate Russia is expanding military infrastructure and preparing for a substantial troop deployment in areas bordering…
Read article
Volkswagen Executives Signal Existential Threat Amidst Internal Survey Findings
A leaked internal survey reveals that a majority of Volkswagen's top executives believe the company's very existence is at risk, citing challenges…
Read article
Russian Frigate Fires Warning Shots Near British Yacht in English Channel
An incident involving a Russian warship and a British yacht in the English Channel has raised concerns about escalating military tensions in…
Read article
Spanish High-Speed Rail Faces Downturn: Nearly 20% Passenger Drop Post-Adamuz Accident
Data reveals a significant decline in high-speed rail ridership in Spain during the first four months of 2026, attributed to infrastructure issues…
Read articleWiki relacionada

Understanding Large Language Models (LLMs)
An introduction to Large Language Models (LLMs), their architecture, capabilities, limitations, and real-world applications in AI.
Read article
Understanding LLM Context Windows
An in-depth look at Large Language Model context windows, their importance, limitations, and how they impact AI applications.
Read article
Comprendiendo los Modelos Llama 3: Una Visión Integral
Explore la familia de modelos Llama 3, detallando su arquitectura, capacidades, limitaciones y aplicaciones prácticas en el desarrollo de IA.
Read article
Comprensión de los Modelos de Lenguaje Grandes (LLM)
Una mirada en profundidad a los Modelos de Lenguaje Grandes (LLM), su arquitectura, capacidades, limitaciones e impacto en el desarrollo de la…
Read article